N or Space for next slide, P for previous slide, F for full screen, M for menu
Lec 13: Restricted models
Boaz Barak (instructor), Salil Vadhan (co-instructor), Juan Perdomo (Head TF).
Team: Aditya Mahadevan, Brian Sapozhnikov (surveys), Chan Kang (extension), Gabe Abrams (Ed Tech), Gabe Montague (NAND web), Jessica Zhu (proof workshops), John Shen, Juan Esteller (NAND implementation), Karl Otness, Katherine Binney, Mark Goldstein (clicker expert), Stefan Spataru, Susan Xu, Tara Sowrirajan (mushroom forager), Thomas Orton (Advanced Section)
Slides will be posted online.

Laptops/phones only on last 3 rows please.
Announcements
Schedule changes (less sections more OH).
Midterm grades
Quizzes
Issues
Phases of this course
Phase 0: Strings, functions, sets, representations.
Take away: Comfort manipulating, sets, functions, functions as objects and inputs.
Phase 1: Computing finite aka fixed input functions (NAND, Boolean circuits)
T/A: Distinguish functions and programs, programs as strings and inputs to other programs.
Phase 2: Computing infinite aka unbounded input functions (NAND++,NAND<<,Turing machines,..)
T/A 1: Still, distinguish functions and programs, and programs as strings. Some functions can’t even be computed!
T/A 2: Unimportance of computational model. Think in algorithms not NAND++ (or Python/C/OCaml)
T/A 3: Reductions as way to relate problems’ difficulty.
Next up: Phase 3: Efficient computation, P and NP and Phase 4: Probabilistic computation.
Sipser’s book
Phases 2 (infinite functions) and 3 (efficient computation, P and NP) well covered in Sisper’s book.
Translate Languages to Functions
| This course | Sipser | |
| Computational task: | Computing a function \(F:\{0,1\}^*\rightarrow \{0,1\}\) | Deciding a language \(L \subseteq \{0,1\}^*\) |
| Input: | \(x\in \{0,1\}^*\) | \(x\in \{0,1\}^*\) |
| Goal: | Compute \(F(x)\) | Decide if \(x\in L\) (output \(1\) for “Yes”, \(0\) for “No”) |
Ladder of abstraction
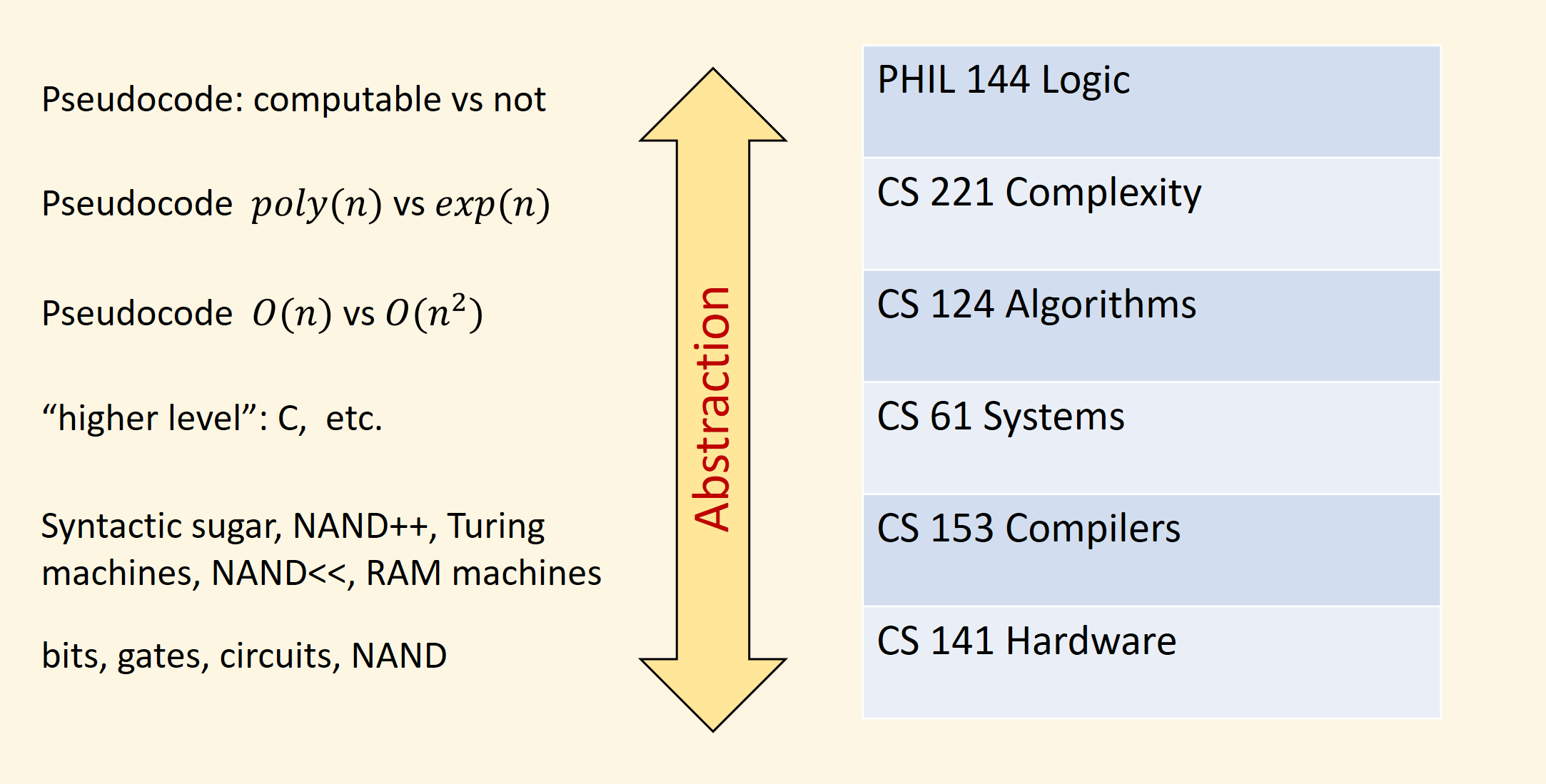
Turing equivalence
NAND++, NAND<<, Turing machines, RAM machines, \(\lambda\) calculus, Game of life, Scratch, C, Fortran, Javascript, PHP, Python, Java, Swift, Ruby, Rust, Go, Perl, Fortran, Lisp, Haskell, OCaml, etc., etc., etc.
Domain Specific Languages (DSL): HTML, CSS, SQL, Shell scripts, Make, Sed, Gherkin, ANTLR , JSON, EMACS Lisp, Map-reduce, Halide, Graphviz dot, XML, UML, VHDL, LaTeX, etc.
“Sub languages”: C preprocessor, type system, templates, regular expressions, list comprehensions, etc. etc.
Why so many languages?
Turing completeness as a bug
We want assurance that:
Search for a string will terminate. (regular expressions.)
Compiler runs in finite time. (context free grammars.)
Program respects type safety. (type system)
Access is granted to right people. (access control rules.)
Database query terminates. (SQL)
Web page is rendedred in finite time (HTML)
Restricted computation mechanism
Want formalisms that are:
- Expressive enough to capture our use cases.
- Restricted enough so that we can verify semantic properties: [
- Halting: Does program halt in finite time?
- Equivalence: Do two programs compute the same function?
- Canonization / normalization: Find “canonical” form for program computing a function.
- Emptyness/Zero: Does a program compute a nonzero output? “safety”
- Finiteness: Does a program output 1 on at most a finite number of inputs? “liveness”
]{.fragment .small}
- Halting: Does program halt in finite time?
- Fast evaluation. (time, memory, parallelization)
Today
One example of a restricted formalism: Regular Expressions
- Widely used in practice
- Extremely efficient implementation
- Elegant theory
- Can certify many semantic properties (halting, finiteness, canonization, emptyness, finitenes,..)
Regular expressions
Def: Regular expression \(exp\) is one of:
- \(0\), \(1\) or \("\,"\)
- \((exp')(exp'')\)
- \(exp' | exp''\)
- \((exp')^*\).
- (Also \(\emptyset\) )
\(\Phi_{exp}(x)=1\) iff \(x\) matches \(exp\).
Example: \((00|11)^*\) corresponds to \(\Phi(x)=1\) iff \(x_{2i+1}=x_{2i}\) for all \(i\).
Question
Which of the following regular expressions captures the set of strings that contain \(010\) as a substring:
a. \((010)^*\)
b. \((001100)^*\)
c. \((010)(0|1)^*\)
d. \((0|1)^*(010)(0|1)^*\)
Question 2: Give a regular expression for the function \(F\) s.t. \(F(x)=1\) is \(x\) does not contain \(010\) as a substring. Hint: Not containing \(010\) means every \(1\) cannot be “isolated” apart from at beginning and end.
No isolated \(1\)’s: \(noisol= \left(\;(0^*)11(1^*)(0^*)\; \right)^*\)
Answer: = \(("\,"|1)\;\; noisol \;\; ("\,"|1)\) Also: \(1^*((0^*)11)^*1^*\)
Decidability of regular expressions
Thm 1: There is an algorithm \(P\) such that \(P(exp,x)=1\) iff \(\Phi_{exp}(x)=1\).
Proof: On input \(exp,x\) do the following:
- If \(exp\) is \(0\), \(1\) or \("\,"\): trivial
- If \(exp=exp'|exp''\) return \(P(exp',x) \vee P(exp'',x)\)
- If \(exp = exp' exp''\) return \(\vee_{i=0}^{|x|-1}P(exp',x_0\cdots x_i)P(exp',x_{i+1}\cdots x_{n-1})\)
- If \(exp = (exp')^*\), return \(1\) if \(exp="\,"\). Otherwise return \(\vee_{i=0}^{|x|-2}P(exp,x_0\cdots x_i)P(exp',x_{i+1}\cdots x_{n-1})\)
Analysis: All recursive calls are either for shorter expressions or shorter strings.
Beyond mere decidability
Thm 2: For every regular expression \(exp\), \(\exists\) algorithm \(P_{exp}\) computing \(\Phi_{exp}\) and moreover:
* On input \(x \in \{0,1\}^*\), \(P_{exp}\) runs in \(O(n)\) time, and makes single pass over \(x\).
* \(P_{exp}\) maintains a constant amount of working memory.
\(P_{exp}\) is known as Finite State Machine (FSM) or Deterministic Finite Automata (DFA).
\(k\) bits of working memory = \(K=2^k\) states.
\(P\) is function \(F:[K] \times \{0,1\} \rightarrow [K]\).
Start at initial state \(s_0=0\), then \(s_1 = F(s_0,x_0)\), \(s_2=F(s_1,x_1)\), \(s_3=F(s_2,x_2)\), \(\ldots\).
Some states designated as accepting (i.e., output \(1\)).
Prooof of Thm 2
Thm 2: For every regular expression \(exp\), \(\exists\) algorithm \(P_{exp}\) computing \(\Phi_{exp}\) and moreover:
* On input \(x \in \{0,1\}^*\), \(P_{exp}\) runs in \(O(n)\) time, and makes single pass over \(x\).
* \(P_{exp}\) maintains a constant amount of working memory.
Proof outline:
- Construct a more efficient recursive algorithm for \(P_{exp}\).
- Transform to form above via dynamic programming and memoization.
Recursive algorithm for regexp match
Lemma: Given \(exp\) and \(\sigma \in \{0,1\}\), can contstruct \(exp[\sigma]\) such that \(\Phi_{exp[\sigma]}(x)=\Phi_{exp}(x \sigma)\) for every \(x\in \{0,1\}^*\).
Example: \(exp=10011|1000\), \(exp[1]=1001\).
Question: If \(exp = (011010)^*\), what is \(exp[0]\)?
a. \((01101)^*\)
b. \((01101) | (011010)^*\)
c. \((011010)^*(01101)\)
d. \((01101)(011010)^*\)
Recursive algorithm for regexp match
Lemma: Given \(exp\) and \(\sigma \in \{0,1\}\), can contstruct \(exp[\sigma]\) such that \(\Phi_{exp[\sigma]}(x)=\Phi_{exp}(x \sigma)\) for every \(x\in \{0,1\}^*\).
Proof:
- If \(exp=0010\), \(exp[0]=001\), \(exp[1]=\emptyset\)
- If \(exp= exp'|exp''\), \(exp[\sigma] = exp'[\sigma] | exp''[\sigma]\).
- If \(exp = (exp')(exp'')\) then \(exp[\sigma] = (exp')(exp''[\sigma])\), (if \(exp''\) matches \("\,"\) then add \(|exp'[\sigma]\) )
- If \(exp= (exp')^*\) \(\equiv "\," | (exp')^*exp'\) then \(exp[\sigma] = (exp')^*(exp'[\sigma])\).
Recursive algorithm for regexp match
Algorithm \(R\):
Input: \(exp\), \(x\in \{0,1\}^n\).
Operation:
- If \(x="\,"\) return \(1\) iff \(exp\) matches \("\,"\)
- Let \(\sigma \leftarrow x_{n-1}\)
- Return \(R(exp[\sigma],x_0,\ldots,x_{n-1})\).
Analysis: Recursive call is shorter string \(\Rightarrow\) \(R\) always halts.
Correctness proof by induction:
\(R(exp,x\sigma)\) \(= R(exp[\sigma],x)\) (ind. hyp.) \(= \Phi_{\exp[\sigma]}(x)\) (lem) \(=\Phi_{exp}(x\sigma)\)
Recursive algorithm for regexp match
Algorithm \(R\):
Input: \(exp\), \(x\in \{0,1\}^n\).
Operation:
If \(x="\,"\) return \(1\) iff \(exp\) matches \("\,"\)
Let \(\sigma \leftarrow x_{n-1}\)
Return \(R(exp[\sigma],x_0,\ldots,x_{n-1})\).
Running time: \(T(n)=T(n-1)+O(1)\) \(\Rightarrow\) \(T(n)=O(n)\)
(crucial obs: expression size is always \(C= O(1)\).)
proof by powerpoint
Recap
Thm 2: For every regular expression \(exp\), \(\exists\) algorithm \(P_{exp}\) computing \(\Phi_{exp}\) and moreover:
* On input \(x \in \{0,1\}^*\), \(P_{exp}\) runs in \(O(n)\) time, and makes single pass over \(x\).
* \(P_{exp}\) maintains a constant amount of working memory.
Many tools to perform this conversion. Also known:
Thm 3: If \(\Phi:\{0,1\}^* \rightarrow \{0,1\}\) can be computed by constant space algorithm then \(\Phi = \Phi_{exp}\) for some \(exp\).
Corollary: \(\forall\) \(exp\) \(\exists\) \(\overline{exp}\) s.t. \(\Phi_{\overline{exp}} = \neg \Phi_{exp}\). can you see why?
Corollary: \(\forall\) \(exp',exp''\), \(\exists\) \(exp\) s.t. \(\Phi_{exp} = \Phi_{exp'} \wedge \Phi_{exp''}\). can you see why?
\(a \wedge b = \overline{\overline{a} \vee \overline{b}}\)
Corollary: Can add \(\neg\) and \(\wedge\) syntactic sugar to reg exps.
Non regular functions
Pumping lemma: (informal) If \(w\) matching \(exp\) is long enough can repeat substring of \(w\) arbitrarily many times and still match.
Proof idea: You can’t match a long string without using \(*\) operator.
Pumping Lemma: If \(\Phi_{exp}(w)=1\) and \(|w| \gt n_0\) then \(w=xyz\) with \(|xy| \leq n_0\), \(|y| \geq 1\) and \(\Phi(xy^kz)=1\) for all \(k\in \mathbb{N}\).
Proof:
Non regular languages
Example: \(PAREN: \{ \langle, \rangle \}^* \rightarrow \{0,1\}\)
Semantic properties
Thm: There is algorithm \(EQ(exp',exp'')\) that outputs \(1\) iff \(\Phi_{exp'}=\Phi_{exp''}\).
Proof: Given \(exp',exp''\), can build \(exp\) s.t. \(\Phi_{exp}(x)=1\) iff \(\Phi_{exp'}(x) \neq \Phi_{exp''}(x)\). (Can express \(\neq\) using \(\wedge,\vee,\neg\).)
Reduces to deciding emptyness: Given \(exp\), is \(\Phi_{exp} \equiv 0\). ✔
Corollary: Decide semantic properties of finite state machines.